Siren
Incident response and on-call you run yourself — alerting, escalation, schedules, and a status page.
Something breaks at 2am. The alert fires, the right person gets paged, and if they don't pick up in five minutes it climbs to the next person. That part you already know. The part that stings is the invoice — billed per responder, every month, for a tool you don't control and can't see inside of.
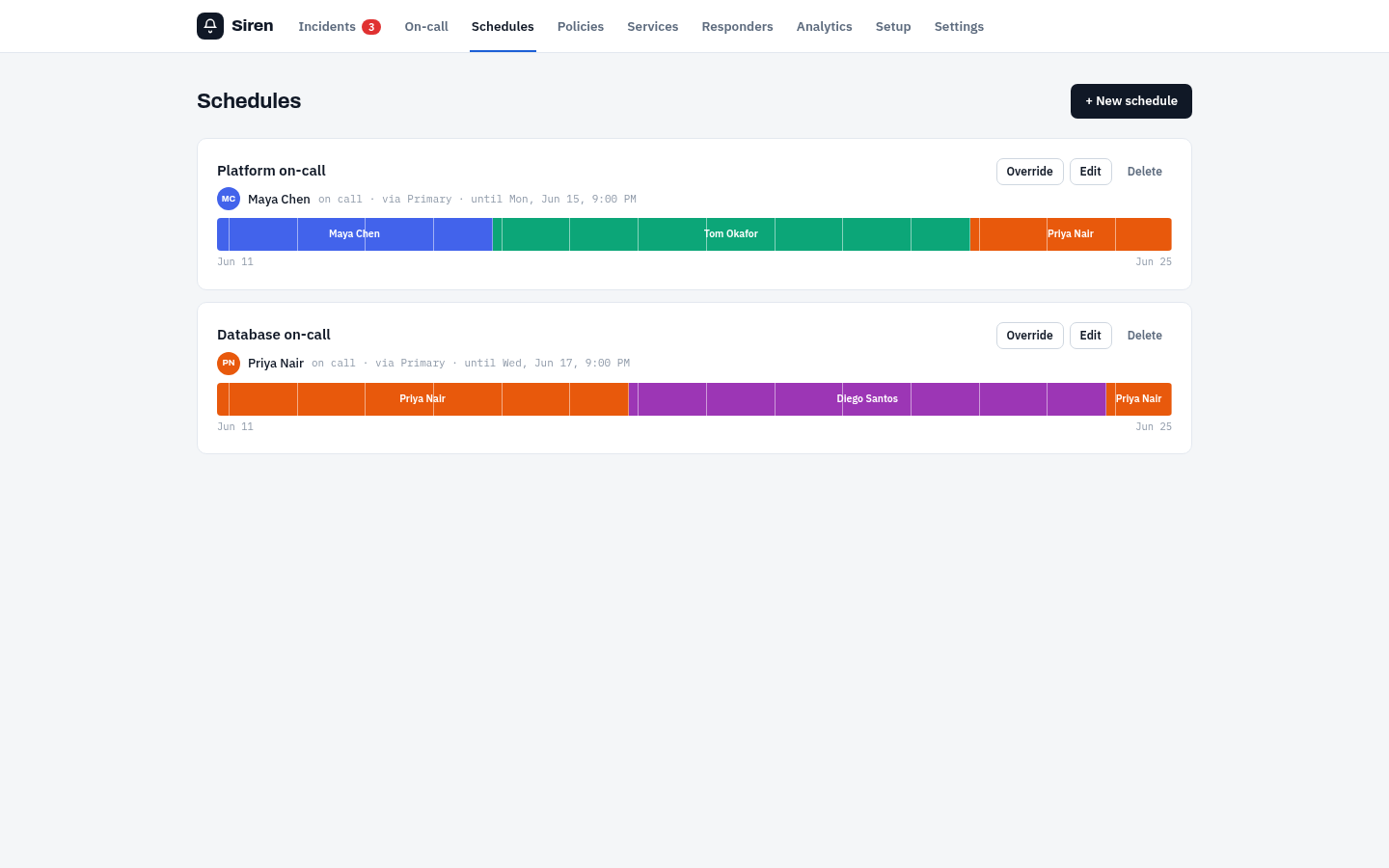
Siren is that whole loop, running on infrastructure you own. Alerts arrive on an endpoint that speaks the PagerDuty Events API v2, so moving over is a URL swap: point Alertmanager, Grafana, or whatever already pages PagerDuty at Siren and keep your existing routing keys. Each alert becomes an incident, the incident pages whoever is on call, and it escalates on a timer until someone acknowledges. Repeat alerts for the same problem group into one incident instead of a flood.
On-call is a real rotation, not a spreadsheet: weekly or daily layers, hour restrictions, and one-tap overrides when someone takes a night or covers a vacation. Escalation policies decide who hears about what and how long to wait before widening the blast radius. A public status page shows your users what's degraded without you writing a word, and the analytics tab tracks the numbers that actually matter — time to acknowledge, time to resolve, who's carrying the load.
It's also built for the way you work now. Siren exposes eight MCP tools, so a connected AI agent is a first-class responder: it can check who's on call, acknowledge and annotate an incident while it investigates, and resolve it with a note that becomes the postmortem trail. Ask it to migrate your existing PagerDuty setup and it follows a built-in recipe — pulls your users, schedules, and escalation policies through the PagerDuty API and recreates them here in minutes.
Copy & Launch gives you your own copy: your incidents, your responders, your escalation rules, no per-seat pricing and nothing phoning home. Email notifications work out of the box; Slack and any other webhook are a paste away.
Talk to it from your AI
Once Siren is on your account, the same AI you used to install it can read its data, send its emails, and change its code — for the life of the project. Try things like:
Every Hatchable project ships with an MCP server scoped to it — how it works.
MCP tools
Trigger a new incident on a service. Pages the current on-call per the service's escalation policy and starts the escalation timer.
Acknowledge a triggered incident — stops the escalation timer and marks that someone is investigating.
Resolve an open incident, optionally recording what fixed it. The note lands on the incident timeline as the postmortem trail.
List incidents, defaulting to the open ones. Filter by status or service.
Full detail for one incident: fields, the complete timeline, and its grouped alerts.
Add an investigation note to an incident timeline — findings, hypotheses, links to dashboards or commits.
Who is on call right now for every schedule, how they got there, and when the shift hands off.
Create an on-call override: a specific responder covers a schedule for a time window.
Features
PagerDuty-compatible alerting
Alerts arrive on a PagerDuty Events API v2 endpoint, so existing monitors move over by changing one URL. Repeat alerts for the same issue group into a single incident by dedup key, and resolving the source auto-closes it.
Escalation policies
Define who gets paged and how long to wait before climbing to the next level. High-urgency incidents escalate on a timer until someone acknowledges; low-urgency ones notify once and stay quiet.
On-call schedules with overrides
Weekly or daily rotations with optional hour restrictions, layered so a deeper rotation backs up the primary. One-tap overrides cover swaps and vacations without rebuilding the schedule.
Public status page
A clean, hosted status page reflects each service in real time — operational, degraded, or major outage — with a rolling history of recent incidents. Toggle it on per service.
Incident analytics
Track mean time to acknowledge and resolve, incident volume per day, the noisiest services, and who is doing the acknowledging — the numbers you need for a calmer on-call.
Agent-native incident response
Eight MCP tools let a connected AI agent triage alongside you: check who is on call, acknowledge, add investigation notes, resolve with a postmortem trail, and even cover a shift. A built-in recipe migrates your PagerDuty config end to end.
What you get
- Source code, deployed to your account on Hatchable
- Your own subdomain (or BYO custom domain on the Builder plan)
- A real Postgres database, scoped to this app
- The ability to make a copy, edit it, and redeploy via your AI tool
- CSV export of your data, any time